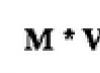Do you know that some letters of the alphabet are found in words more often than others... Moreover, the frequency of use of vowels in the language is higher than consonants.
Which letters of the Russian alphabet are most often or least often found in words used to write text?
Statistics deals with the identification and study of general patterns. With the help of this scientific direction, you can answer the question posed above by counting the number of each letter of the Russian alphabet, the words used, and selecting an excerpt from the works of various authors. For their own interest and for the sake of something to do out of boredom, everyone can do this on their own. I will refer to the statistics of an already conducted study...

Russian alphabet Cyrillic. During its existence, it experienced several reforms, as a result of which the modern Russian alphabet system, including 33 letters, was formed.

o — 9.28%
a — 8.66%
e — 8.10%
and - 7.45%
n — 6.35%
t — 6.30%
p — 5.53%
s — 5.45%
l - 4.32%
in — 4.19%
k — 3.47%
n — 3.35%
m — 3.29%
y - 2.90%
d — 2.56%
I - 2.22%
s — 2.11%
b — 1.90%
z — 1.81%
b — 1.51%
g — 1.41%
th — 1.31%
h — 1.27%
yu — 1.03%
x — 0.92%
f — 0.78%
w — 0.77%
c — 0.52%
sch — 0.49%
f — 0.40%
e — 0.17%
ъ — 0.04%
The Russian letter with the highest frequency of use is the vowel “ ABOUT", as has already been rightly suggested here. There are also typical examples like “ DEFENSE"(7 pieces in one word and nothing exotic or surprising; very common for the Russian language). The high popularity of the letter “O” is largely explained by such a grammatical phenomenon as full vowel. That is, “cold” instead of “cold” and “frost” instead of “scum”.
And at the very beginning of words, the consonant letter “” is most often found P" This leadership is also confident and unconditional. Most likely, the explanation is provided by a large number of prefixes starting with the letter “P”: pere-, pre-, pre-, pri-, pro- and others.
The frequency of use of letters is the basis of cryptanalysis.
In general, there is such a topic - frequency analysis of text. It is argued that for a given language the frequency of occurrence of individual letters in a meaningful text is a stable value. Combinations of two, three (digrams, trigrams) and four letters are also stable.
This fact, in particular, was used in cryptography to break ciphers.
I'm not very good at cryptography, and the only thing that comes to mind is breaking a direct substitution cipher. It must be said that the most primitive cipher is when the characters of the original alphabet used in the message are converted into other characters according to a certain rule. Such ciphers, by the way, could be opened without the use of statistical analysis (where, to reduce the error, the presence of rather large pieces of text is obviously required), but simply by guessing about some words - see the story “The Dancing Men”.
And the final touch (optional). Sometimes (almost always for now) the calculator needs to be provided with a description - what the parameters are, what formulas it uses, and in general, why it’s all for - just like I’m doing now. To do this, an article is written, and the calculator is inserted directly into the article. To write an article, select the menu item “Create...” -> “Article” on the main page of the “My Calculators” section and start writing. To insert a calculator, press the button with the large underlined letter A and select the newly created calculator in the dialog that opens.
Which letter is most often used in Russian? And what is the easiest way to find out and got the best answer
Answer from Viktor Edinovich[guru]
The only correct answer! At one time, any typographer knew from experience which font (letter) was used the most when typing.
Victor Edinovich
Enlightened
(38377)
No. I'm just a former encyclopedist...
Answer from Elizaveta Ventsevich[guru]
I think "A".
Answer from Alexandra Lapikova[guru]
according to the degree of wear on the writer’s keyboard
Answer from YolaFka[guru]
bukaFka AAAAAAAAAAAA))))
Answer from BOBA BOBAHOB[guru]
I think that the letter "X" is evidence? just take a walk down the street
Answer from *
[expert]
the most commonly used 3 letters are U Y X
Answer from On[guru]
probably Kommersant
Answer from Dyusmikeev Valery[guru]
The letter a
Answer from &Ъ[guru]
How everyone jokes. Of course, the letter O!!!
Answer from Pavel Makagonov[guru]
O, then E, then I, then A. Then the consonants N, T, S, R, etc.
I had to do the math based on a large number of texts. Don't trust the hooligans.
Answer from Elena Strathberry[active]
Of course the letter R. Because it is in the middle of the keyboard!! ! 🙂
Answer from Inga zajontz[guru]
we take any dictionary, most of all words starting with “p”, after with “r”, after with “o”, after with “T”, in the end the most characteristic word for Russian is spaciousness and simplicity
according to Dahl
Answer from Alexander Reiser[guru]
Try to guess which letter of the Russian language is most common?
Letter O. Frequency of occurrence – 0.090. That is, in a sequence of 1000 letters, the letter O will appear on average 90 times.
Which letters occupy leading positions and are found most often?
Vowels. They are the ones that are most often found in the Russian language, making our speech “melodious”. Following O are the letters E and E (together, they are not separated, because when writing, they often lose E). Occurrence frequency – 0.072. Behind them are the letters A and I. The frequency of appearance of each of them is 0.062.
Is this enough to decode text? In principle, yes, if we are sure that the sequence of codes contains text in Russian in some of the encodings known or unknown to us. But there is always some probability that the presented sequence of codes has nothing to do with the Russian language. To verify this, you need to use a frequency dictionary of words in the Russian language.
What word do you think occurs most often in the Russian language?
The conjunction I is followed by equally short parts of speech - IN, NOT, OH, ON. But most often, of course, there will be a gap.
The decoded text must be checked for a match using the frequency dictionary. And only with more or less complete coincidence can we say that we are dealing with a text written in Russian.
This gives 100% results if the text is large enough. If we are talking about several words, then the frequency of letters (and even more so words) may be disrupted. What to do in this case? We need to offer the reader several options to choose from. Decode the text using one of the most common vowel letters. Vowels! They will always appear more often than other letters. If the text is encoded in Russian, then success is guaranteed.
In this article we will begin a discussion of an extremely interesting topic - the use of statistics for the analysis of text information. Note that the use of statistics for text analysis is a traditional task.
First, we will present some interesting facts regarding the frequency of occurrence of letters and their combinations in different languages (for more details, see the book). In subsequent articles we will show how to apply more complex methods of analysis and graphical representation.
Frequency characteristics of text messages
So, the text consists of words, words of letters. The number of different letters in each language is limited and the letters can simply be listed. Important characteristics of the text are the repetition of letters, pairs of letters (digrams) and in general m-OK ( m-gram), compatibility of letters with each other, alternation of vowels and consonants and some others. It is remarkable that these characteristics are quite stable. We leave the question “why” behind the scenes.
Using the system STATISTICA You can check these patterns, for example, in Internet texts.
The idea is to count the number of occurrences of each n m possible m-gram in sufficiently long plaintexts T=t 1 t 2 …t l, made up of letters of the alphabet ( a 1 , a 2 , ..., a n). At the same time, consecutive m-grams of text:
t 1 t 2 ...t m , t 2 t 3 ... t m+1 , ..., t i-m+1 t l-m+2 ...t l.
If – number of occurrences m-grams a i1 a i2 ...a im in the text T, A L– total number of counted m-gram, then experience shows that for sufficiently large L frequencies
for this m-grams differ little from each other.
Because of this, the relative frequency (1) is considered to be an approximation of the probability P (a i1 a i2 ...a im) appearance of this m-grams in a randomly selected place in the text (this approach is adopted in the statistical determination of probability).
Below are tables of letter frequencies (in percentage) for a number of European languages. Data taken from the book.
| Letter of the alphabet | French | German | English language | Spanish | Italian language |
|---|---|---|---|---|---|
| A | 7.68 | 5.52 | 7.96 | 12.90 | 11.12 |
| B | 0.80 | 1.56 | 1.60 | 1.03 | 1.07 |
| C | 3.32 | 2.94 | 2.84 | 4.42 | 4.11 |
| D | 3.60 | 4.91 | 4.01 | 4.67 | 3.54 |
| E | 17.76 | 19.18 | 12.86 | 14.15 | 11.63 |
| F | 1.06 | 1.96 | 2.62 | 0.70 | 1.15 |
| G | 1.10 | 3.60 | 1.99 | 1.00 | 1.73 |
| H | 0.64 | 5.02 | 5.39 | 0.91 | 0.83 |
| I | 7.23 | 8.21 | 7.77 | 7.01 | 12.04 |
| J | 0.19 | 0.16 | 0.16 | 0.24 | - |
| K | - | 1.33 | 0.41 | - | - |
| L | 5.89 | 3.48 | 3.51 | 5.52 | 5.95 |
| M | 2.72 | 1.69 | 2.43 | 2.55 | 2.65 |
| N | 7.61 | 10.20 | 7.51 | 6.20 | 7.68 |
| O | 5.34 | 2.14 | 6.62 | 8.84 | 8.92 |
| P | 3.24 | 0.54 | 1.81 | 3.26 | 2.66 |
| Q | 1.34 | 0.01 | 0.17 | 1.55 | 0.48 |
| R | 6.81 | 7.01 | 6.83 | 6.95 | 6.56 |
| S | 8.23 | 7.07 | 6.62 | 7.64 | 4.81 |
| T | 7.30 | 5.86 | 9.72 | 4.36 | 7.07 |
| U | 6.05 | 4.22 | 2.48 | 4.00 | 3.09 |
| V | 1.27 | 0.84 | 1.15 | 0.67 | 1.67 |
| W | - | 1.38 | 1.80 | - | - |
| X | 0.54 | - | 0.17 | 0.07 | - |
| Y | 0.21 | - | 1.52 | 1.05 | - |
| Z | 0.07 | 1.17 | 0.05 | 0.31 | 1.24 |
Some difference in frequency values in the tables given in various sources is explained by the fact that frequencies significantly depend not only on the length of the text, but also on its nature. For example, in technical texts the rare letter F can become quite common due to the frequent use of words such as function, differential, diffusion, coefficient, etc.
Even greater deviations from the norm in the frequency of use of individual letters are observed in some works of art, especially in poetry. Therefore, to reliably determine the average frequency of letters, it is desirable to have a set of different texts borrowed from various sources. However, as a rule, such deviations are insignificant, and to a first approximation they can be neglected.
A visual representation of the frequencies of letters is given by the occurrence diagram. So, for the English language, in accordance with the table, such a diagram is shown in Fig. 1. To build it, we used the system STATISTICA.

For the Russian language, the frequencies (in descending order) of the characters of the alphabet in which they are identified E c Yo, b With Kommersant, and there is also a space sign (-) between words, are given in the following table (see).
| -
0.175 | ABOUT
0.090 | HER
0.072 | A
0.062 |
| AND
0.062 | T
0.053 | N
0.053 | WITH
0.045 |
| R
0.040 | IN
0.038 | L
0.035 | TO
0.028 |
| M
0.026 | D
0.025 | P
0.023 | U
0.021 |
| I
0.018 | Y
0.016 | Z
0.016 | b, b
0.014 |
| B
0.014 | G
0.013 | H
0.012 | Y
0.010 |
| X
0.009 | AND
0.007 | YU
0.006 | Sh
0.006 |
| C
0.004 | SCH
0.003 | E
0.003 | F
0.002 |
Based on the table, we obtain the following frequency diagram (Fig. 2).

There is a mnemonic rule for memorizing the ten most common letters of the Russian alphabet. These letters make up the ridiculous word HAY. You can also suggest a similar way of memorizing common letters in the English language, for example, using the word TETRIS-HONDA (see table).
The frequency characteristics of bigrams, trigrams and fourgrams of meaningful texts are also stable.
We present tables of bigram frequencies for the Russian and English languages (the tables are borrowed from the book). For convenience, they are divided into four parts according to the following scheme:
| Part 1 | Part 2 |
| Part 3 | Part4 |
|
Part 1 |
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | IN | G | D | E | AND | Z | AND | Y | TO | L | M | N | ABOUT | P | |
| A | 2 | 12 | 35 | 8 | 14 | 7 | 6 | 15 | 7 | 7 | 19 | 27 | 19 | 45 | 5 | 11 |
| B | 5 | 9 | 1 | 6 | 6 | 2 | 21 | |||||||||
| IN | 35 | 1 | 5 | 3 | 3 | 32 | 2 | 17 | 7 | 10 | 3 | 9 | 58 | 6 | ||
| G | 7 | 3 | 3 | 5 | 1 | 5 | 1 | 50 | ||||||||
| D | 25 | 3 | 1 | 1 | 29 | 1 | 1 | 13 | 1 | 5 | 1 | 13 | 22 | 3 | ||
| E | 2 | 9 | 18 | 11 | 27 | 7 | 5 | 10 | 6 | 15 | 13 | 35 | 24 | 63 | 7 | 16 |
| AND | 5 | 1 | 6 | 12 | 5 | 6 | ||||||||||
| Z | 35 | 1 | 7 | 1 | 5 | 3 | 4 | 2 | 1 | 2 | 9 | 9 | 1 | |||
| AND | 4 | 6 | 22 | 5 | 10 | 21 | 2 | 23 | 19 | 11 | 19 | 21 | 20 | 32 | 8 | 13 |
| Y | 1 | 1 | 4 | 1 | 3 | 1 | 2 | 4 | 5 | 1 | 2 | 7 | 9 | 7 | ||
| TO | 24 | 1 | 4 | 1 | 4 | 1 | 1 | 26 | 1 | 4 | 1 | 2 | 66 | 2 | ||
| L | 25 | 1 | 1 | 1 | 1 | 33 | 2 | 1 | 36 | 1 | 2 | 1 | 8 | 30 | 2 | |
| M | 18 | 2 | 4 | 1 | 1 | 21 | 1 | 2 | 23 | 3 | 1 | 3 | 7 | 19 | 5 | |
| N | 54 | 1 | 2 | 3 | 3 | 34 | 58 | 3 | 1 | 24 | 67 | 2 | ||||
| ABOUT | 1 | 28 | 84 | 32 | 47 | 15 | 7 | 18 | 12 | 29 | 19 | 41 | 38 | 30 | 9 | 18 |
| P | 7 | 15 | 4 | 9 | 1 | 46 | ||||||||||
|
Part 2 |
|||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R | WITH | T | U | F | X | C | H | Sh | SCH | Y | b | E | YU | I | |
| A | 26 | 31 | 27 | 3 | 1 | 10 | 6 | 7 | 10 | 1 | 2 | 6 | 9 | ||
| B | 8 | 1 | 6 | 1 | 11 | 2 | |||||||||
| IN | 6 | 19 | 6 | 7 | 1 | 1 | 2 | 4 | 1 | 18 | 1 | 2 | 3 | ||
| G | 7 | 2 | |||||||||||||
| D | 6 | 8 | 1 | 10 | 1 | 1 | 1 | 5 | 1 | 1 | |||||
| E | 39 | 37 | 33 | 3 | 1 | 8 | 3 | 7 | 3 | 3 | 1 | 1 | 2 | ||
| AND | 1 | ||||||||||||||
| Z | 3 | 1 | 2 | 4 | 4 | ||||||||||
| AND | 11 | 29 | 29 | 3 | 1 | 17 | 3 | 11 | 1 | 1 | 1 | 3 | 17 | ||
| Y | 3 | 10 | 2 | 1 | 3 | 2 | |||||||||
| TO | 10 | 3 | 7 | 10 | 1 | ||||||||||
| L | 3 | 1 | 6 | 4 | 1 | 3 | 20 | 4 | 9 | ||||||
| M | 2 | 5 | 3 | 9 | 1 | 2 | 5 | 1 | 1 | 3 | |||||
| N | 1 | 9 | 9 | 7 | 1 | 5 | 2 | 36 | 3 | 5 | |||||
| ABOUT | 43 | 50 | 39 | 3 | 2 | 5 | 2 | 12 | 4 | 3 | 2 | 3 | 2 | ||
| P | 41 | 1 | 6 | 2 | 2 | ||||||||||
|
Part 3 |
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | IN | G | D | E | AND | Z | AND | Y | TO | L | M | N | ABOUT | P | |
| R | 55 | 1 | 4 | 4 | 3 | 37 | 3 | 1 | 24 | 3 | 1 | 3 | 7 | 56 | 2 | |
| WITH | 8 | 1 | 7 | 1 | 2 | 25 | 6 | 40 | 13 | 3 | 9 | 27 | 11 | |||
| T | 35 | 1 | 27 | 1 | 3 | 31 | 1 | 28 | 5 | 1 | 1 | 11 | 56 | 4 | ||
| U | 1 | 4 | 4 | 4 | 11 | 2 | 6 | 3 | 2 | 8 | 5 | 5 | 5 | 1 | 5 | |
| F | 2 | 2 | 2 | 1 | ||||||||||||
| X | 4 | 1 | 4 | 1 | 3 | 1 | 2 | 3 | 4 | 3 | 3 | 4 | 18 | 5 | ||
| C | 3 | 7 | 10 | 2 | 1 | |||||||||||
| H | 12 | 23 | 13 | 2 | 6 | |||||||||||
| Sh | 5 | 11 | 14 | 1 | 2 | 2 | 2 | |||||||||
| SCH | 3 | 8 | 6 | 1 | ||||||||||||
| Y | 1 | 9 | 1 | 3 | 12 | 2 | 4 | 7 | 3 | 6 | 6 | 3 | 2 | 10 | ||
| b | 2 | 4 | 1 | 1 | 2 | 2 | 2 | 6 | 3 | 13 | 2 | 4 | ||||
| E | 1 | 1 | ||||||||||||||
| YU | 2 | 1 | 2 | 1 | 3 | 1 | 1 | 1 | 1 | 1 | 3 | |||||
| I | 1 | 3 | 9 | 1 | 3 | 3 | 1 | 5 | 3 | 2 | 3 | 3 | 4 | 6 | 3 | 6 |
|
Part 4 |
|||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R | WITH | T | U | F | X | C | H | Sh | SCH | Y | b | E | YU | I | |
| R | 1 | 5 | 9 | 16 | 1 | 1 | 1 | 2 | 8 | 3 | 5 | ||||
| WITH | 4 | 11 | 82 | 6 | 1 | 1 | 2 | 2 | 1 | 8 | 17 | ||||
| T | 26 | 18 | 2 | 10 | 1 | 11 | 21 | 4 | |||||||
| U | 7 | 14 | 7 | 1 | 8 | 3 | 2 | 9 | 1 | ||||||
| F | 1 | 1 | |||||||||||||
| X | 3 | 4 | 2 | 2 | 1 | 1 | |||||||||
| C | 1 | 1 | |||||||||||||
| H | 7 | 1 | 1 | 1 | |||||||||||
| Sh | 1 | 1 | |||||||||||||
| SCH | 1 | ||||||||||||||
| Y | 3 | 9 | 4 | 1 | 16 | 1 | 2 | ||||||||
| b | 1 | 11 | 3 | 1 | 4 | 1 | 3 | 1 | |||||||
| E | 1 | 9 | |||||||||||||
| YU | 1 | 1 | 7 | 1 | 1 | 4 | |||||||||
| I | 3 | 6 | 10 | 2 | 1 | 4 | 1 | 1 | 1 | 1 | 1 | ||||

Nice tables k-gram is easy to obtain using the texts of electronic versions of many books contained on CDs.
To obtain more accurate information about plaintexts, you can build and analyze tables k-gram at k>2, but for educational purposes it is enough to limit ourselves to bigrams. Unevenness k-gram (and even words) is closely related to a characteristic feature of open text - the presence in it of a large number of repetitions of individual text fragments: roots, endings, suffixes, words and phrases. So, for the Russian language, such familiar fragments are the most common bigrams and trigrams:
ST, BUT, EN, TO, NA, OV, NI, RA, VO, KO
STO, ENO, NOV, TOV, OVO, OVA
Information about the compatibility of letters, that is, about the preferred connections of letters with each other, is useful, which can be easily obtained from bigram frequency tables.
This refers to a table in which the most preferred “neighbors” are located to the left and right of each letter (in descending order of frequency of the corresponding bigrams). Such tables usually also indicate the proportion of vowels and consonants (in percentage) preceding (or following) a given letter.
Combination of Russian letters:
| G | WITH | Left | On right | G | WITH | |
|---|---|---|---|---|---|---|
| 3 | 97 | l, d, k, t, v, r, n | A | l, n, s, t, r, v, k, m | 12 | 88 |
| 80 | 20 | i, e, y, i, a, o | B | o, s, e, a, r, y | 81 | 19 |
| 68 | 32 | i, t, a, e, i, o | IN | o, a, i, s, s, n, l, r | 60 | 40 |
| 78 | 22 | r, y, a, i, e, o | G | o, a, p, l, i, v | 69 | 31 |
| 72 | 28 | r, i, y, a, i, e, o | D | e, a, i, o, n, y, p, v | 68 | 32 |
| 19 | 81 | m, i, l, d, t, r, n | E | n, t, r, s, l, v, m, i | 12 | 88 |
| 83 | 17 | r, e, i, a, y, o | AND | e, i, d, a, n | 71 | 29 |
| 89 | 11 | o, e, a, and | Z | a, n, c, o, m, d | 51 | 49 |
| 27 | 73 | r, t, m, i, o, l, n | AND | s, n, c, i, e, m, k, h | 25 | 75 |
| 55 | 45 | b, v, e, o, a, i, s | TO | o, a, i, p, y, t, l, e | 73 | 27 |
| 77 | 23 | g, v, s, i, e, o, a | L | i, e, o, a, b, i, yu, y | 75 | 25 |
| 80 | 20 | i, s, a, i, e, o | M | i, e, o, y, a, n, p, s | 73 | 27 |
| 55 | 45 | d, b, n, o | N | o, a, i, e, s, n, y | 80 | 20 |
| 11 | 89 | r, p, k, v, t, n | ABOUT | c, s, t, r, i, d, n, m | 15 | 85 |
| 65 | 35 | in, with, y, a, i, e, o | P | o, p, e, a, y, i, l | 68 | 32 |
| 55 | 45 | i, k, t, a, p, o, e | R | a, e, o, i, y, i, s, n | 80 | 20 |
| 69 | 31 | s, t, v, a, e, i, o | WITH | t, k, o, i, e, b, s, n | 32 | 68 |
| 57 | 43 | h, y, i, a, e, o, s | T | o, a, e, i, b, v, r, s | 63 | 37 |
| 15 | 85 | p, t, k, d, n, m, r | U | t, p, s, d, n, y, w | 16 | 84 |
| 70 | 30 | n, a, e, o, and | F | and, e, o, a, e, o, a | 81 | 19 |
| 90 | 10 | y, e, o, a, s, and | X | o, i, s, n, v, p, r | 43 | 57 |
| 69 | 31 | e, yu, n, a, and | C | i, e, a, s | 93 | 7 |
| 82 | 18 | e, a, y, i, o | H | e, i, t, n | 66 | 34 |
| 67 | 33 | b, y, s, e, o, a, i, v | Sh | e, i, n, a, o, l | 68 | 32 |
| 84 | 16 | e, b, a, i, y | SCH | e, i, a | 97 | 3 |
| 0 | 100 | m, r, t, s, b, c, n | Y | l, x, e, m, i, v, s, n | 56 | 44 |
| 0 | 100 | n, s, t, l | b | n, k, v, p, s, e, o, and | 24 | 76 |
| 14 | 86 | s, s, m, l, d, t, r, n | E | n, t, r, s, k | 0 | 100 |
| 58 | 42 | b, o, a, i, l, y | YU | d, t, sch, c, n, p | 11 | 89 |
| 43 | 57 | o, n, r, l, a, i, s | I | c, s, t, p, d, k, m, l | 16 | 84 |

When analyzing the compatibility of letters with each other, one should keep in mind the dependence of the appearance of letters in plain text on a significant number of preceding letters. To analyze these patterns, the concept of conditional probability is used.
Observations of plaintexts show that the following inequalities hold for conditional probabilities: p(a i1)≠p(a i1 /a i2), p(a i1 /a i2)≠p(a i1 /a i2 a i3),....
The question of the dependence of the letters of the alphabet in plain text on previous letters was systematically studied by the famous Russian mathematician A. A. Markov (1856 – 1922). He proved that the occurrences of letters in plaintext cannot be considered independent of each other. In this regard, A. A. Markov noted another stable pattern of open texts associated with the alternation of vowels and consonants. He calculated the frequency of occurrence of vowel-vowel bigrams ( G, G), vowel-consonant ( G, With), consonant-vowel ( With, G), consonant-consonant ( With, With) in Russian text with a length of 10 5 characters. The calculation results are shown in the following table:
| G | WITH | Total | |
|---|---|---|---|
| G | 6588 | 38310 | 44898 |
| WITH | 38296 | 16806 | 55102 |
From this table it can be seen that the Russian language is characterized by alternation of vowels and consonants, and the relative frequencies can serve as approximations of the corresponding conditional and unconditional probabilities:
p(G/With)≈0.663, p(With/G)≈0.872,
p(G)≈0.432, p(With)≈0.568.
After A. A. Markov, the dependence of the appearance of letters in a text, following several previous ones, was studied by methods of information theory by K. Shannon. In fact, they showed, in particular, that such a dependence is noticeable to a depth of approximately 30 characters, after which it is practically absent.
Proportion of vowels in a literary text:

The above patterns apply to ordinary “readable” plaintexts used in human communication. As noted earlier, these patterns play a big role in cryptanalysis. In particular, they are used in the construction of formalized criteria for plaintext, which make it possible to apply methods of mathematical statistics in the problem of plaintext recognition in a message stream. When using special alphabets, similar studies of the frequency characteristics of “open texts” that arise, for example, during machine-to-machine information exchange or in data transmission systems are required. In these cases, constructing formalized criteria for “clear text” is a much more difficult task.
As an example, we give the frequency characteristics of the letters of the English alphabet that are part of the ASCII code.
In addition to cryptography, the frequency characteristics of clear messages are significantly used in other areas. For example, a computer keyboard, a typewriter or a Linotype is a wonderful embodiment of the idea of speeding up typing, associated with optimizing the arrangement of the letters of the alphabet relative to each other, depending on the frequency of their use.
Literature:
Alferov A.P. et al., "Cryptography"
Yaglom A.M., Yaglom I.M., Probability and information, M.: Nauka, 1973.
Baudouin C., Elements de cryptographie / Ed. Pedone A. – Paris, 1939.
Friedman W. F., Callimahos D., Military cryptanalysis, Part i, Vol 2, Aegean Park Press, Laguna Hills CA, 1920.
The method proposed by Al-Kindi is easier to explain from the point of view of the Russian alphabet. First of all, it is necessary to study a sufficiently long passage of text in Russian, or several passages of different texts, in order to establish the frequency of occurrence of each letter of the alphabet. In russian language O- the most common letter, after it e, then A and so on, as indicated in the table. Then we will study the ciphertext and determine the frequency of occurrence of each character in it. For example, if the most frequent character in the ciphertext YU, then most likely it should be replaced with the letter O. If the second most common character in the ciphertext E, then it should probably be replaced with e, and so on. Thanks to Al-Kindi's method, known as frequency cryptanalysis, there is no need to check each of the billions of potential keys. Instead, you can decrypt a message simply by analyzing the frequency of the characters in it.
| Letter | Frequency % | Letter | Frequency % | Letter | Frequency % | Letter | Frequency % |
|---|---|---|---|---|---|---|---|
| ABOUT | 11,08 | R | 4,45 | Y | 1,96 | X | 0,89 |
| HER | 8,41 | IN | 4,33 | b | 1,92 | Sh | 0,81 |
| A | 7,92 | TO | 3,36 | Z | 1,75 | YU | 0,61 |
| AND | 6,83 | M | 3,26 | G | 1,74 | E | 0,38 |
| N | 6,72 | D | 3,05 | B | 1,71 | SCH | 0,37 |
| T | 6,18 | P | 2,81 | H | 1,47 | C | 0,36 |
| WITH | 5,33 | U | 2,80 | Y | 1,12 | F | 0,19 |
| L | 5,00 | I | 2,13 | AND | 1,05 | Kommersant | 0,02 |
However, frequency cryptanalysis does not completely solve the problem of breaking monoalphabetic ciphers. Its applicability depends on the size and nature of the text. The average letter frequencies of any language will not always correspond to the letter frequencies of a particular text. For example, a short message discussing the influence of the atmosphere on the movement of zebras in Africa, “Because of the ozone holes from Zanzibar to Zambia and Zaire, zebras run in zigzags,” if encrypted with a monoalphabetic cipher, could not be decrypted using simple frequency cryptanalysis. Since the letter h in this message it occurs an order of magnitude more often than in simple speech. A rare letter in technical texts f can become quite common due to the frequent use of words such as function, differential, diffusion, coefficient, etc.
If it is not possible to decipher a cryptogram using simple frequency cryptanalysis (for example, if the message is too short), Al-Kindi suggests using characteristic combinations of letters or, conversely, the incompatibility of certain letters with each other. For example, the most common bigrams (groups of two letters) of the Russian language: st, But, en, That, on, ov, neither, ra, in, co. Statistics on the combination of vowels and consonants are important. For example, before letters b, s, ъ and after uh vowels cannot appear, and any vowel is followed by a consonant with a probability of 87%. Also a clue for a cryptanalyst can be the generally accepted introductory words that are used in almost every language. For example, in Arabic, “In the name of God, the merciful and merciful” (بسم الله الرحمن الرحيم) was often used. When deciphering poems, you can use rhymes and feet.
Arabic letters: their order and repetition
Al-Kindi provides a table with the frequencies of letters of the Arabic alphabet calculated in a sample of seven sheets of text.
There are 28 letters in the Arabic alphabet. Of these, 27 can denote consonant sounds, 3 (ﺍ (/aː/), ﻭ (/uː/), ﻱ (/iː/)) - long vowel sounds, there are no letters denoting short vowels (for example, in the word Muhammad they are written only four consonants: محمد). Thus, purely consonant letters predominate in Arabic writing. However, this fact does not contradict the statement indicated at the beginning of the treatise that the most common letter in the writing of any language is, as a rule, a vowel, since in Arabic it is ﺍ (/aː/).